프로덕션 환경에서 AI 에이전트를 운영하는 가장 큰 도전 과제 중 하나는 불예측한 장애 상황에 대응하는 것입니다. LLM(Large Language Model) API 호출 실패, 네트워크 타임아웃, 리소스 부족 등 다양한 이유로 에이전트가 정상 작동하지 못할 수 있습니다. 이러한 상황에서 시스템이 완전히 실패하는 것이 아니라 ‘우아한 성능 저하(graceful degradation)’를 제공하는 것이 매우 중요합니다. Fallback 전략은 이러한 신뢰성을 확보하기 위한 핵심 메커니즘입니다.
Fallback 시스템을 갖춘 에이전트는 다음과 같은 이점을 제공합니다. 첫째, 사용자 경험의 연속성을 보장합니다. 주 시스템이 실패하더라도 대체 경로(fallback path)를 통해 사용자에게 어떤 형태의 응답을 제공할 수 있으므로 완전한 서비스 중단을 방지할 수 있습니다. 둘째, 비용 효율성을 높입니다. 고가의 고성능 모델이 실패할 때 더 저렴한 모델로 자동 전환하면 비용을 절감하면서도 서비스를 지속할 수 있습니다. 셋째, 시스템의 복원력(resilience)을 증대시킵니다. 단일 실패 지점(single point of failure)이 전체 시스템을 마비시키지 못하도록 분산된 대체 경로를 준비합니다.
예를 들어, 전자상거래 플랫폼에서 AI 기반 추천 엔진이 고장난 상황을 생각해봅시다. Fallback 전략이 없다면 사용자는 추천 상품을 볼 수 없어 구매 결정에 어려움을 겪게 됩니다. 하지만 Fallback 메커니즘이 있다면, 인기 상품 목록이나 카테고리별 베스트셀러 같은 사전 계산된 추천안을 신속하게 제공할 수 있습니다. 이렇게 하면 AI 시스템의 정교함은 덜하지만 사용자는 여전히 유용한 정보를 얻을 수 있습니다.
2. Fallback 아키텍처 설계 패턴
Fallback 아키텍처를 설계할 때는 여러 가지 패턴을 조합하여 사용할 수 있습니다. 첫 번째 패턴은 ‘Model Fallback(모델 폴백)’입니다. 이는 주 모델(primary model)이 실패할 때 대체 모델(secondary model)로 자동 전환하는 방식입니다. 예를 들어, GPT-4o 호출이 실패하면 Claude Opus로 전환하고, 그것도 실패하면 더 가벼운 Claude Haiku로 전환하는 식입니다. 이 접근법의 장점은 최대한의 기능성을 유지한다는 것이지만, 각 모델마다 다른 비용 구조와 응답 품질을 고려해야 합니다.
두 번째 패턴은 ‘Strategy Fallback(전략 폴백)’으로, 전체 처리 전략을 변경하는 방식입니다. 예를 들어, 실시간 정보가 필요한 질의에 대해 먼저 웹 검색 + LLM 조합을 시도하지만 실패하면, 캐시된 지식 베이스만 사용하는 전략으로 전환합니다. 또는 복잡한 다단계 추론(multi-step reasoning)이 실패하면 단순한 규칙 기반 시스템으로 대체하는 방식도 있습니다.
세 번째 패턴은 ‘Cached Response Fallback(캐시된 응답 폴백)’입니다. 시스템이 동일하거나 유사한 요청에 대해 이전에 생성한 응답을 캐시해두었다가, 현재 요청이 실패할 때 이 캐시된 응답을 제공하는 방식입니다. 이 방법은 구현이 간단하고 응답 속도가 빠르다는 장점이 있지만, 최신 정보를 제공하지 못할 수 있다는 단점이 있습니다.
네 번째 패턴은 ‘Default Response Fallback(기본 응답 폴백)’으로, 모든 것이 실패했을 때 미리 정의된 기본 응답(default response)이나 부분적 응답(partial response)을 제공하는 방식입니다. 예를 들어, 날씨 예보 API가 실패하면 ‘현재 날씨 정보를 사용할 수 없습니다’라는 메시지를 제공하거나, 일반적인 안내 메시지를 보내는 것입니다. 이는 최후의 안전장치 역할을 합니다.
3. 실전 구현 사례 및 모범 사례
실제 구현 예시를 살펴봅시다. 고객 지원 챗봇을 운영하는 기업의 경우, Fallback 전략이 매우 중요합니다. 주 시스템은 GPT-4o를 사용하여 복잡한 고객 문의에 대해 정교한 응답을 생성합니다. 그러나 API 제한(rate limit)에 도달하거나 OpenAI 서비스가 일시적으로 중단되는 상황에 대비해야 합니다. 이 기업은 다음과 같은 Fallback 계층을 구현했습니다.
첫 번째 시도: GPT-4o 호출 (timeout: 5초). 성공하면 그 응답을 사용하고, 2초 안에 응답이 없으면 다음 단계로 넘어갑니다. 두 번째 시도: Claude 3 Sonnet 호출 (timeout: 5초). 이는 GPT-4o보다 저렴하면서도 여전히 고품질의 응답을 제공합니다. 세 번째 시도: 캐시된 유사 질의의 이전 응답 검색. 고객의 질의와 유사한 이전 질의가 있다면 그에 대한 응답을 활용합니다. 네 번째 시도: 지정된 자주 묻는 질문(FAQ) 목록에서 관련 항목 검색. 마지막: 사람(human agent)에게 에스컬레이션합니다.
이러한 구조를 실제로 구현하려면 일부 핵심 기술 결정을 내려야 합니다. 첫째, 어느 정도의 지연(latency)까지 허용할 것인지를 결정해야 합니다. 사용자는 보통 3-5초 이내의 응답을 기대하므로, fallback 단계를 너무 많이 두면 전체 응답 시간이 초과될 수 있습니다. 따라서 병렬 처리(parallel processing)를 고려할 수 있습니다. 예를 들어, 주 모델 호출과 함께 2초 타이머를 설정하고, 2초 후에도 응답이 없으면 즉시 대체 모델을 호출하는 방식입니다(race condition). 둘째, 각 Fallback 단계의 비용과 품질을 신중하게 평가해야 합니다. 비용을 절감하기 위해 품질을 너무 많이 포기하면 사용자 만족도가 떨어집니다.
4. 모니터링 및 자동 복구 메커니즘
Fallback 시스템이 제대로 작동하려면 강력한 모니터링 인프라가 필수입니다. 시스템 관리자는 어떤 Fallback이 얼마나 자주 발생하는지, 각 단계에서 얼마나 많은 요청이 실패하는지를 실시간으로 추적해야 합니다. 이를 위해 구조화된 로깅(structured logging)을 구현합니다. 각 요청마다 다음과 같은 정보를 기록합니다: 요청 ID, 타임스탬프, 시도한 모델, 성공 여부, 응답 시간, 에러 메시지(실패 시).
모니터링 메트릭으로는 다음과 같은 것들이 중요합니다. 첫째, Fallback Rate: 전체 요청 중 몇 퍼센트가 주 모델에서 실패했는가? 이것이 갑자기 증가하면 주 모델에 문제가 있을 가능성이 높습니다. 둘째, Fallback Success Rate: Fallback된 요청 중 몇 퍼센트가 최종적으로 성공했는가? 이것이 낮으면 전체 Fallback 체인이 제대로 작동하지 않을 수 있습니다. 셋째, End-to-End Latency Distribution: 전체 응답 시간의 분포. Fallback으로 인해 응답 시간이 크게 증가했는가? 넷째, Cost per Request: 각 요청당 평균 비용. 자주 Fallback되면 더 비용이 들 수 있습니다.
자동 복구 메커니즘은 이러한 모니터링 데이터를 기반으로 작동합니다. 예를 들어, 만약 특정 LLM API의 실패율이 30분 동안 50% 이상으로 유지된다면, 자동으로 해당 API로의 요청을 일시적으로 중단하고 완전히 Fallback 모델로 전환합니다. 이를 ‘Circuit Breaker Pattern’이라고 부릅니다. 또한, 특정 시간 동위에 너무 많은 요청이 실패하면, 시스템은 자동으로 Rate Limit를 낮추거나(backoff), 덜 중요한 기능부터 제한합니다(graceful degradation).
알림(alerting) 시스템도 중요합니다. Fallback이 과도하게 발생하거나, 모든 Fallback이 실패하는 상황이 발생하면, 엔지니어링 팀에 즉시 알림을 보내야 합니다. 이러한 알림은 단순히 메일이 아니라, 즉각적인 반응을 요구하는 중요도에 따라 Slack, PagerDuty 같은 실시간 커뮤니케이션 도구를 통해 전달되어야 합니다. 또한 ‘Post-mortem’ 분석을 통해 왜 Fallback이 발생했는지, 향후 이를 방지하려면 어떻게 해야 하는지를 정기적으로 검토합니다.
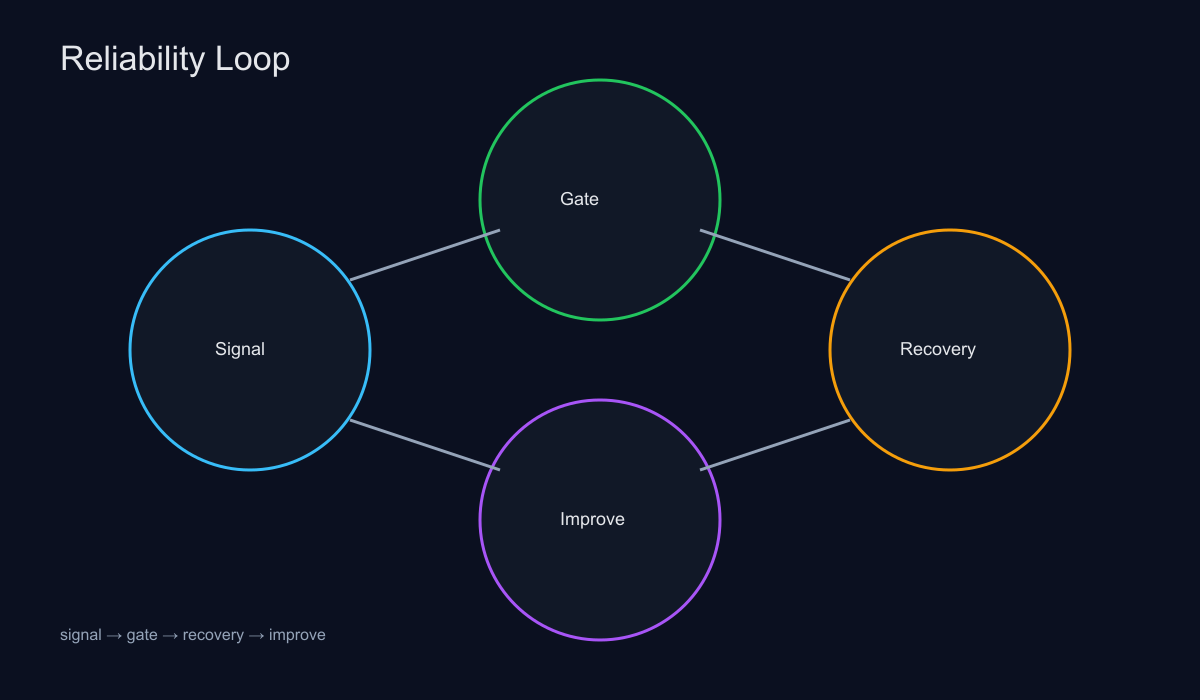
AI 에이전트는 ‘결과’보다 운영 리스크가 더 큰 문제다. 작은 오류가 연결되면 품질과 비용이 동시에 무너진다. 그래서 신뢰성 설계는 모델 선택보다 더 중요한 전략이 된다. 이 글은 새로운 카테고리 AI 에이전트 신뢰성 설계의 첫 글로, 신호(Signal)–게이트(Gate)–회복(Recovery)–개선(Improvement) 루프를 기반으로 운영 체계를 정리한다.
English note: reliability is not a promise; it is a process that keeps failures small.
목차
신뢰성의 정의: 정확도보다 운영 안정성이 먼저다
신호 계층 설계: 어떤 지표가 먼저 울려야 하는가
게이트와 승인: 실패를 작게 만드는 규칙
회복 루프: 복구 시간과 범위를 줄이는 구조
위험-영향 매트릭스: 자동/검토/에스컬레이션 분리
비용-품질 예산: 운영은 숫자로 고정된다
증거 패키지: 재현 가능한 로그 구조
실전 시나리오: 고객지원·리서치·콘텐츠
운영 체크포인트: 팀이 합의해야 할 7가지
마무리: 신뢰성은 루틴이다
1. 신뢰성의 정의: 정확도보다 운영 안정성이 먼저다
많은 팀이 “정확도”를 신뢰성으로 오해한다. 하지만 운영에서 신뢰성은 예측 가능성이다. 어떤 상황에서 시스템이 멈추고, 어떤 상황에서 사람에게 넘기는지 명확해야 한다. If users can predict the system’s behavior, they will trust it.
신뢰성은 세 가지 질문으로 정의된다.
실패가 발생했을 때 얼마나 작게 멈추는가
실패가 감지되었을 때 얼마나 빠르게 복구되는가
복구 이후 왜 실패했는지 재현 가능한가
이 세 가지가 충족되면, 모델이 완벽하지 않아도 운영은 안정적이다.
English summary: accuracy is a metric, reliability is a system.
2. 신호 계층 설계: 어떤 지표가 먼저 울려야 하는가
신뢰성 설계의 첫 단계는 신호 계층이다. 모든 지표를 동시에 보면 운영은 멈춘다. 그래서 우선순위를 만든다.
1차 신호: latency, error rate
2차 신호: cost per request, cache hit ratio
3차 신호: quality score, grounding ratio
English note: if everything is a priority, nothing is.
신호 계층이 있으면 “어떤 지표가 먼저 경고를 울려야 하는지”가 명확해진다. 또한 신호는 게이트와 연결되어야 한다. 예: latency가 기준을 넘으면 고급 모델 승격을 제한하고, error rate가 기준을 넘으면 자동 재시도를 줄인다.
실전에서는 신호 안정화 창(window) 을 둔다. 3~5분 이동평균이나 P95/P99 기준을 사용하면 스파이크를 노이즈로 처리할 수 있다. This avoids false alarms while still catching real failures.
3. 게이트와 승인: 실패를 작게 만드는 규칙
게이트는 신뢰성의 핵심이다. 게이트는 “성공”을 보장하는 장치가 아니라, 실패가 확산되는 것을 막는 장치다. 다음과 같은 게이트가 기본이다.
비용 게이트: 예산 초과 시 모델 승격 제한
품질 게이트: 근거 부족 시 요약 대신 출처 제공
정책 게이트: 금지 표현 감지 시 즉시 중단
English note: gates are not friction; they are guardrails.
게이트가 작동하면 실패는 작은 영역에서 멈춘다. 운영자가 판단할 수 있는 크기로 축소되는 것이다. 또한 게이트 로그가 중요하다. 왜 중단되었는지 기록하지 않으면, 같은 실패가 반복된다. Example: policy gate triggered, riskScore=0.82, reason=PII-risk.
게이트 임계값은 “고정값”이 아니다. 월 1회 리뷰 주기를 두고, 실제 운영 데이터로 조정해야 한다. This keeps the system aligned with reality.
아래 그림은 신호-게이트-회복 루프를 요약한다.
4. 회복 루프: 복구 시간과 범위를 줄이는 구조
회복 루프는 장애가 발생했을 때의 리듬이다. 고정된 리듬이 없으면 팀은 상황마다 다른 방식으로 대응한다. 다음과 같은 15분 루프가 효과적이다.
0~5분: 정상 지표 확인 및 사용자 영향 확인
5~10분: 증거 패키지 수집 및 원인 가설 정리
10~15분: 안전 모드 전환 또는 우회 경로 적용
English note: a fixed rhythm beats improvisation.
회복 루프는 커뮤니케이션과 연결되어야 한다. “현재 상태 → 다음 조치 → 확인 지표”를 한 줄로 공유하면, 팀은 같은 방향을 본다. One clear status line beats ten scattered messages.
또한 회복 루프는 안전 모드와 연결해야 한다. 예: 장애 중에는 고비용 기능을 끄고, 핵심 경로만 유지한다. This keeps the system alive while you debug.
5. 위험-영향 매트릭스: 자동/검토/에스컬레이션 분리
운영에서 중요한 것은 “같은 실패”가 아니다. 위험도와 영향도가 다르다. 그래서 매트릭스를 만든다.
Low risk / Low impact: 자동 통과
High risk / Low impact: 샘플 검토
High risk / High impact: 즉시 에스컬레이션
English note: risk is probability, impact is damage.
이 매트릭스는 게이트 임계값을 결정하는 기준이 된다. 예를 들어 금융·개인정보·권한 변경 요청은 impact가 높으므로, 무조건 사람 승인을 요구한다. When impact is high, automation must slow down.
아래 그림은 위험-영향 매트릭스 예시다.
6. 비용-품질 예산: 운영은 숫자로 고정된다
신뢰성 설계는 예산 없이 존재할 수 없다. 비용/지연/품질 예산을 먼저 고정해야 한다.
비용 예산: 요청당 평균 비용 상한
지연 예산: P95 latency 목표
품질 예산: 샘플 평가 기준
English note: budgets are rules, not reports.
예산이 고정되면, 워크플로는 그 안에서 최적화된다. 운영자는 “어떤 기능을 유지하고, 어떤 기능을 줄일지”를 숫자로 결정할 수 있다. Without budgets, teams argue; with budgets, teams decide.
실전에서는 예산 히스토리가 중요하다. 어느 구간에서 비용이 튀었는지 기록이 없으면 개선이 느려진다. 또한 버짓 히트맵을 만들어 시간대별 비용을 시각화하면, 가장 효율적인 라우팅 전략을 찾을 수 있다.
7. 증거 패키지: 재현 가능한 로그 구조
신뢰성의 핵심은 재현 가능성이다. 이를 위해 증거 패키지가 필요하다.
필수 구성:
requestId, sessionId
toolCalls, toolOutputs
policyVersion, modelVersion
decisionTrace, finalOutput
English note: evidence is the backbone of recovery.
증거 패키지가 없으면 같은 실패를 다시 분석할 수 없다. 특히 모델과 정책 버전이 기록되지 않으면, 같은 입력에서도 결과가 달라지는 문제가 발생한다. Version control is reliability control.
실전 팁: 위험도가 높은 실행만 장기 보관하고, 저위험 실행은 요약만 남긴다. This balances cost and traceability.
8. 실전 시나리오: 고객지원·리서치·콘텐츠
A) 고객지원
캐시 + 경량 모델로 1차 대응
고위험 요청은 사람에게 에스컬레이션
근거 부족 시 안전 응답
B) 리서치
retrieval 품질이 핵심이므로 게이트 강화
근거 부족 시 요약 대신 출처만 제공
비용 예산 초과 시 top-k 축소
C) 콘텐츠
초안 자동 생성 후 검증 게이트 통과 시 발행
유사 주제 감지 시 각도 변경
샘플 리뷰로 품질 드리프트 감시
English summary: workflows must change by context, not by habit.
추가로 콘텐츠 운영에서는 에디터 큐가 필요하다. 일정 비율은 사람이 검토하고, 나머지는 자동 발행한다. A small manual queue prevents large silent failures.
9. 운영 체크포인트: 팀이 합의해야 할 7가지
신뢰성 설계는 기술이 아니라 합의다. 최소한 다음 7가지에 합의해야 한다.
어떤 신호가 위험 경고인가
게이트 임계값은 어떻게 정하는가
어떤 요청이 사람 승인 대상인가
회복 루프의 리듬은 몇 분인가
안전 모드는 무엇을 끄고 무엇을 유지하는가
증거 패키지 보관 기간은 얼마인가
월간 리뷰에서 무엇을 바꿀 것인가
English note: reliability is a shared contract.
이 합의가 없으면 운영은 개인의 감각에 의존하고, 결과는 일관성이 없어질 수밖에 없다.
10. 마무리: 신뢰성은 루틴이다
AI 에이전트는 완벽하지 않다. 그래서 신뢰성은 “완벽한 모델”이 아니라 반복 가능한 루틴으로 만들어진다. 신호를 정의하고, 게이트로 실패를 작게 만들고, 회복 루프로 복구를 빠르게 하면 운영은 안정된다.
English closing: trust is a system of repeatable checks.
11. 실전 아키텍처 패턴: Reliability를 구조로 고정하기
신뢰성 설계는 추상 개념이 아니라 아키텍처 패턴으로 고정되어야 한다. 다음 세 가지 패턴이 가장 현실적이다.
(1) Dual-Path Execution
같은 요청을 두 경로로 처리한다. 하나는 빠른 경로(cheap path), 다른 하나는 안전 경로(safe path)다. 빠른 경로는 비용을 줄이고, 안전 경로는 정확도를 높인다. The system chooses the path based on risk score. 위험도가 높으면 자동으로 안전 경로로 라우팅한다.
(2) Deferred Decision Pattern
모델이 즉시 결정을 내리지 않고, “보류” 상태로 남겨 사람이 승인하도록 한다. 예: 데이터 변경, 권한 수정, 결제 처리. This prevents irreversible mistakes. 보류가 많아지면 비용이 늘지만, 신뢰성은 크게 향상된다.
(3) Evidence-First Workflow
출력보다 근거 패키지를 먼저 만들게 한다. 도구 호출과 근거가 충분히 확보되기 전에는 최종 답을 만들지 못하게 한다. This flips the order: evidence first, answer second. 운영에서 가장 안전한 패턴이다.
이 패턴을 적용하면, 정책 변경이나 모델 교체가 있어도 “구조”는 흔들리지 않는다. Reliability is architecture, not luck.
12. 측정과 리뷰: 신뢰성은 숫자로 유지된다
신뢰성은 감으로 유지되지 않는다. 측정과 리뷰가 반복돼야 한다. 다음 지표를 꾸준히 추적한다.
Recovery Time Objective (RTO)
Escalation Rate (사람 개입 비율)
Gate Rejection Rate (게이트 차단 비율)
Evidence Completeness Score
English note: what you don’t measure will silently decay.
리뷰는 주간과 월간으로 분리한다. 주간 리뷰는 빠른 개선에 집중하고, 월간 리뷰는 정책과 예산 변경을 다룬다. 예: “이번 달 게이트 차단 비율이 8% 상승했다면, 어떤 지표가 경고를 먼저 줬는가?” This turns metrics into decisions.
또 하나의 중요한 지점은 메트릭 리밸런싱이다. 초기에 중요했던 지표가 시간이 지나면 의미가 약해질 수 있다. 그래서 분기마다 “우리가 진짜로 봐야 할 지표가 무엇인지”를 재정의한다. When priorities shift, metrics must shift too.
13. 실패 시나리오에서 배우기: 작은 실패를 설계하는 법
현실의 실패 시나리오는 대부분 비슷한 패턴을 가진다. 예: API 타임아웃, 데이터 누락, 캐시 불일치, 예산 초과. 중요한 것은 실패를 작은 범위에서 멈추게 하는 것이다.
예를 들어 캐시가 실패했을 때 전체 요청을 실패시키는 대신, 제한된 범위에서만 fallback을 허용한다. This keeps the blast radius small. 또한 timeout은 단계별로 분리한다. Step-level timeout, turn-level timeout, session-level timeout을 분리하면 장애가 확산되지 않는다.
가장 위험한 실패는 조용한 실패다. 사용자에게는 정상처럼 보이지만, 내부적으로 품질이 떨어지는 상태다. 이를 막기 위해 품질 샘플링과 레이블링을 주기적으로 수행한다. Silent failures are the most expensive.
14. 조직 운영 관점: 사람과 프로세스의 신뢰성
신뢰성 설계는 기술만으로 완성되지 않는다. 사람과 프로세스가 함께 움직여야 한다. 운영에서 중요한 것은 “개인”이 아니라 “역할”이다. On-call, reviewer, gate owner 같은 역할이 명확해야 한다.
또한 프로세스는 단순해야 한다. 너무 복잡한 규칙은 실제 상황에서 무시된다. The best process is the one people actually follow. 따라서 정책을 줄이고, 자동화를 늘리고, 인간의 판단이 필요한 지점만 남겨야 한다.
마지막으로, 신뢰성은 문화다. 실패를 공개하고, 개선을 공유하고, 실수를 기록하는 문화를 만들면 시스템은 점점 강해진다. Reliability grows where learning is safe.
15. 운영 데이터 설계: 신호가 왜곡되지 않게 만드는 방법
신뢰성은 데이터 품질에 의존한다. 신호가 왜곡되면 게이트도 잘못 작동한다. 그래서 운영 데이터는 일관된 스키마로 수집해야 한다. 예를 들어 모든 로그에 requestId, model, policyVersion, latency, cost를 포함하면, 분석이 쉬워진다. Schema consistency is reliability for data.
또한 로그는 구조화되어야 한다. JSON 로그는 수집과 분석에 유리하고, 정규화된 필드를 통해 자동 경보를 만들 수 있다. Unstructured logs are slow to audit. 구조화는 운영 속도를 높인다.
데이터 신뢰성을 위해 “샘플 검증 루프”를 둔다. 매일 1~2%의 샘플을 사람이나 규칙 엔진이 리뷰하면 드리프트를 빠르게 감지할 수 있다. This is cheaper than full manual review but still catches real issues.
16. 권한과 책임: 시스템이 실수하지 않도록 만드는 마지막 안전장치
AI 에이전트는 도구와 데이터에 접근한다. 따라서 권한 관리가 곧 신뢰성이다. 최소 권한 원칙을 적용하고, 권한 변경은 반드시 승인 루프를 거친다. Least privilege is a reliability pattern, not just a security rule.
또한 책임 분리가 필요하다. “누가 이 정책을 바꿀 수 있는가”와 “누가 게이트를 해제할 수 있는가”를 분리하면, 운영 리스크가 줄어든다. Separation of duties reduces silent failures.
실전에서는 권한 세션 만료를 짧게 두는 것이 효과적이다. 예: 민감한 도구는 15분 세션으로 제한한다. This reduces long-lived risk.
17. 요약적 관점: 신뢰성은 느리게 쌓이지만 빨리 무너진다
신뢰성은 한 번의 프로젝트로 완성되지 않는다. 작은 실패를 줄이고, 반복 가능한 루틴을 만드는 과정이 필요하다. 그래서 가장 중요한 것은 “꾸준함”이다. Consistency beats brilliance in operations.
마지막으로 기억해야 할 점은 사용자 경험이다. 사용자는 모델의 내부 구조를 모른다. 하지만 “항상 예측 가능한 행동”을 경험하면, 신뢰는 자연스럽게 쌓인다. Trust is earned in small moments, not in big claims.
18. 사례로 보는 신뢰성 개선: 고객지원 에이전트의 실제 리디자인
한 고객지원 에이전트 시스템은 “정확도는 높지만 운영 신뢰성이 낮은” 전형적인 문제를 겪었다. 주말에는 비용이 급등했고, 월요일에는 응답 지연이 폭증했다. The system looked smart but behaved unpredictably.
개선은 다음 4단계로 진행됐다.
신호 계층 재정의: latency와 비용을 1차 신호로 올리고, 품질 지표는 2차로 내려 우선순위를 재배치했다. This reduced noisy alerts.
게이트 임계값 조정: 고급 모델 승격 기준을 risk score 기반으로 변경했다. 결과적으로 고비용 요청이 27% 감소했고, 품질은 유지됐다.
회복 루프 고정: 장애 발생 시 15분 루프를 강제했다. 각 단계의 책임자와 커뮤니케이션 템플릿을 정해 혼란을 줄였다.
증거 패키지 표준화: 모든 실행에 동일 포맷의 로그를 남겼다. This enabled fast postmortems and repeatable fixes.
결과는 명확했다. 평균 비용은 32% 감소했고, P95 latency는 18% 개선되었으며, 운영자가 “예측 불가능한 상황”을 보고하는 비율이 절반 이하로 줄었다. The biggest win was not the metrics, but the confidence of the team.
19. 운영 체크: 작은 습관이 신뢰성을 만든다
운영은 결국 습관의 합이다. 매일 5분씩 신호 대시보드를 확인하고, 주간 회고에서 “이번 주 가장 위험했던 사건 1개”를 공유하면 신뢰성은 서서히 상승한다. Small habits create large stability.
또한 지식을 기록하는 문화가 중요하다. 장애 원인과 해결 과정을 간단히 기록해 두면, 새로운 팀원이 합류했을 때도 빠르게 같은 수준의 운영 품질을 유지할 수 있다. Knowledge is the cheapest reliability upgrade.
20. 끝맺음 메모
신뢰성은 특정 기능이 아니라 시스템 전체의 “태도”다. 작은 실패를 인정하고, 이를 구조로 흡수하는 조직은 시간이 갈수록 강해진다. Reliability is the sum of small disciplined choices.